TWiki> IVOA Web>IvoaDataModel>ObservationProvenanceDataModel (2022-07-20, MathieuServillat)
IVOA Web>IvoaDataModel>ObservationProvenanceDataModel (2022-07-20, MathieuServillat) EditAttach
EditAttach
Provenance Data Model
A workpackage inside the DM WG back to DM main page Acknowledgements: supports from ASTERICS/DADI WP, CTA project, GAVO Project, ASOV OV-France, Paris Astronomical Data Center (PADC)Current Documents
IVOA Provenance DM has become a recommendation on 2020-04-11 after validation by the DM WG, TCG board and Executive board: https://www.ivoa.net/documents/ProvenanceDM/ PR v2: started in july 2019 (WD period was open for 4 weeks from 2019-06-14) PR v1: proposed recommendation at the IVOA College Park meeting in November 2018 Previous version of the working draft: NamespaceGoal
This workpackage is focused on the description on the data processing applied to provide astronomical data. We stick to the point of view of a user who wants to select appropriate data sets for his science study. In most cases the user will start with science ready data products but will have to discover progenitor data and possibly reprocess the original data. The purpose is to outline the main blocks of information that can summarise how a dataset was produced using some specific facility, in particular observation conditions. This will be articulated with the Dataset Metadata DM, a Data Model that federates the developments of existing models: Observation Core Components DM, Spectral DM, Characterisation DM, Photometry DM.Discussions
Meetings
- Provenance discussions at IVOA Interop, May 2019; Notes, ChangeList
- Provenance discussion for PR update / Asterics focus ProvFocusAsterics ProvFocusAstericsExamples
- Provenance meeting, Paris, August 28th - 30th ProvDayAug2018
- Participation to the Provenance Week 2018, London, 2018, July 9-13 ProvWeekJuly2018
- Provenance discussions at InterOp Victoria, 2018, May 28th - June 1st ProvDiscussionMay2018
- Provenance telecon, 2018, May 2nd, ProvTeleconMay2018
- Provenance short Meeting in Edinburg during Asterics Tech Forum see the Asterics Hackhaton Page here
- Provenance short Meeting in Postdam , before RDA meeting in Berlin ProvDayMarch2018
- Provenance meeting, Potsdam, January 18th - 19th ProvDayJanuary2018
- Provenance discussions at InterOp Santiago, 2017, October
- Provenance telecon, 2017, September 5th, ProvTeleconSeptember2017
- Provenance day, Paris, 2017, July 27th afternoon and 28th ProvDayJuly2017
- Provenance day, Montpellier, 2017, May 3rd afternoon and 4th ProvDayMay2017
- Provenance meeting, Strasbourg, 2017, March 23rd at the Asterics Tech Forum ProvDayMarch2017
- Provenance day, Strasbourg, 2016, December 13th ProvDayDec2016
- Provenance discussions at InterOp Trieste, 2016, October 16th - 23rd ProvDiscussionOctober016
- Provenance telecon, 2016, October 12th ProvTeleconOctober2016
- Provenance telecon, 2016, September 14th ProvTeleconSeptember2016
- Provenance day, Paris , 2016, July 20th ProvDayJuly2016
- Provenance day, Heidelberg , 2016, June 14th ProvDayJune2016
- Provenance day, Paris , 2016, April 14th ProvDayApril2016
Associated publications
- Servillat et al., 2018, "Provenance as a requirement for large-scale complex astronomical instruments", ADASS XXVII proceedings (Santiago 2017), ASP Conf. Ser
- Sanguillon et al, 2018, "Provenance Tools for Astronomy", ADASS XXVII proceedings (Santiago 2017), ASP Conf. Ser
- Riebe et al. 2017, "A Provenance Data Model for Astronomy", ADASS XXVI proceedings (Trieste 2016), ASP Conf. Ser
- Servillat et al. 2017, "Structuring metadata for the Cherenkov Telescope Array", ADASS XXVI proceedings (Trieste 2016), ASP Conf. Ser
- Sanguillon et al. 2016, "IVOA Provenance data model: hints from the CTA Provenance prototype", ADASS XXV proceedings (Sydney 2015), ASP Conf. Ser
Presentations
- IVOA College Park, USA, November 2018:
- IVOA Victoria, Canada, May 2018:
- DM session [M. Servillat - Status]
- DAL session [F. Bonnarel - Status]
- IVOA Santiago, Chile, October 2017
- ADASS XXVII Santiago, Chile, October 2017 [M. Sanguillon - Tools poster] [M. Servillat - CTA] [M. Servillat - lightning talk]
- IVOA Shanghai, Chine, May 2017 [M. Louys - Status]
- IVOA Trieste, Italy, October 2016 [K. Riebe - Status] [F. Bonnarel - Prov for HiPS] [M. servillat - CTA]
- ADASS XXVI Trieste, Italy, October 2016 [K. Riebe - ProvDM] [M. Servillat - CTA]
- IVOA Cape Town, South Africa, May 2016 [K. Riebe - Intro] [K. Riebe - RAVE] [M. Sanguillon - Pollux] [M. Servillat - CTA] [M. Louys - ProvDM]
- ADASS XXV Sydney, Australia, October 2015 [M. Sanguillon - CTA]
- IVOA Sesto, Italy, June 2015 [K. Riebe - Status] [M. Servillat - CTA]
- IVOA Banff, Canada, October 2014 [M. Demleitner]
Previous IVOA efforts (before 2013)
- By following the Legacy link you will have a compilation of previous efforts on Provenance made during the stone and copper ages of the IVOA.
Example Companion documents
ProvSerialisationExampleUse-cases
-
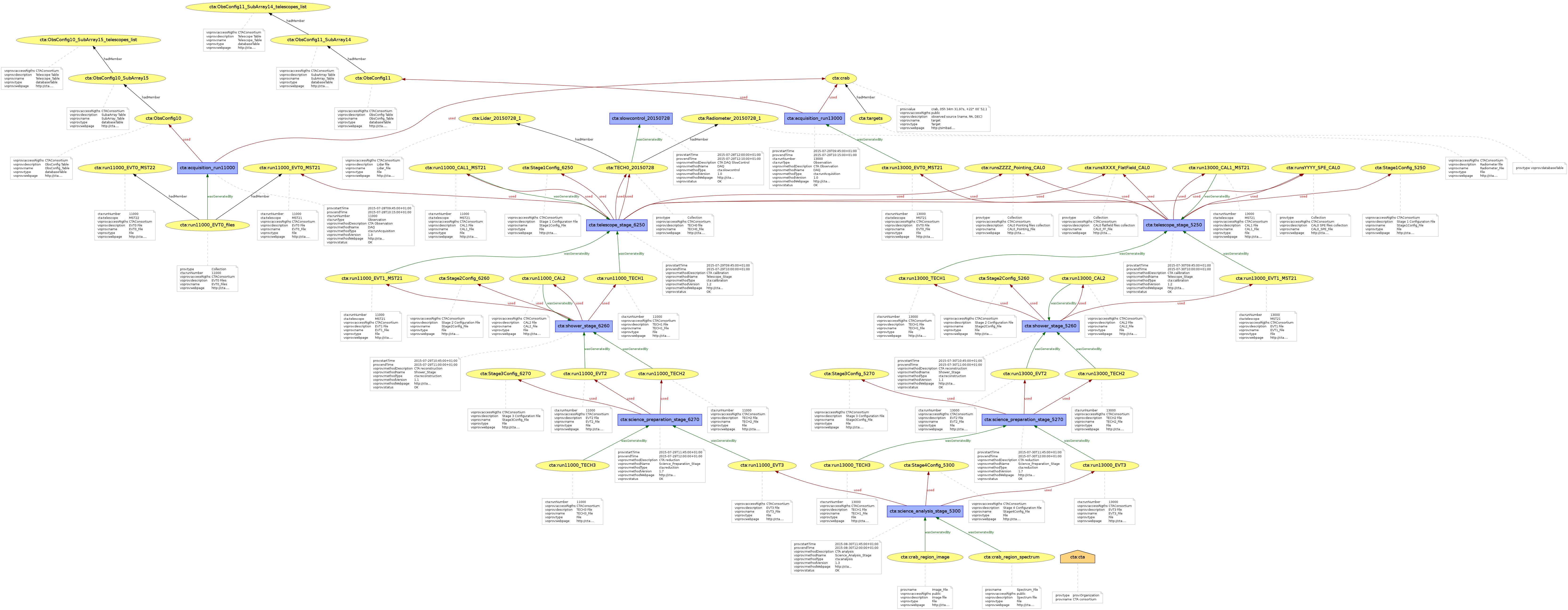
CTA project
The Cherenkov Telescope Array (CTA) is the next generation ground-based very high energy gamma-ray instrument. It will provide a deep insight into the non-thermal high-energy universe. Contrary to previous Cherenkov experiments, it will serve as an open observatory providing data to a wide astrophysics community, with the requirement to propose self-described data products to users that may be unaware of the Cherenkov astronomy specificities. Cherenkov telescopes indirectly detect gamma-rays by observing the flashes of Cherenkov light emitted by particle cascades initiated when the gamma-rays interact with nuclei in the atmosphere. The main difficulty is that charged cosmic rays also produce such cascades in the atmosphere, which represent an enormous background compared to genuine gamma-ray-induced cascades. Monte Carlo simulations of the shower development and Cherenkov light emission and detection, corresponding to many different observing conditions, are used to model the response of the detectors. With an array of such detectors the shower is observed from several points and, working backwards, one can figure out where the origin, energy and time of the incident particle. Extensive simulations are needed in order to perform this reconstruction. Because of this complexity in the detection process, Provenance information of data products are necessary to the user to perform a correct scientific analysis. Provenance concepts are relevant for different aspects of CTA :Data diffusion: the diffused data products have to contain all the relevant context information with the assumptions made as well as a description of the methods and algorithms used during the data processing.
Pipeline : the CTA Observatory must ensure that data processing is traceable and reproducible.
Instrument Configuration : the characteristics of the instrument at a given time have to be available and traceable (hardware changes, measurements of e.g. a reflectivity curve of a mirror, ...)
USE CASE 1 :
Reprocess a data product: The different processing steps and relevant parameters used in the original analysis are required, as well as the progenitor. -
Pollux and Polarbase databases : http://pollux.graal.univ-montp2.fr and http://polarbase.irap.omp.eu
Pollux is a synthetic spectra database while Polarbase is an observed spectra one. Both databases are accessible by their web interface or via the OV protocol : SSA. Concerning the synthetic spectra, the provenance tracing is important to know on the one hand the workflow which has generated each synthetic spectrum and on the second hand some important input parameters which characterize the result. The SSA protocol with the FORMAT=METADATA query allows users to query the database with different parameters defined by the provider (including provenance entities or activities). Currently users can query Pollux on the atmosphere model (which corresponds to the first code of the workflow), the effective temperature, the gravity, the mass and the microturbulence which are input parameters of this code (all the selected parameters avalaible on the web site are not implemented in the SSA protocol). All the provenance data are stored in the header of the Pollux spectrum in a home readable format.
Concerning the observed spectra, the provenance of them is important and the provenance characteritics are mostly described by the ObsConfig part of the spectral datal model. But all observed spectra offered to users are not raw data. They have often been transformed by programs (calibration, ...). No provenance information is given about those programs.
The provenance data model which can be included in a lot of OV data models such as the spectral data model allows providers and users to use the same format of description of the data provenance (PROV-N for example) and to translate this description in other formats (JSON, SVG, ...) via existing tools.
USE CASE 1 :
Show me a list of synthetic spectra satisfying :
- domain of wavelength = visible
- domain of effective temperature = [4000, 5000]
USE CASE 2 :
Show me a list of synthetic spectra satisfying :
- code for model atmosphere = MARCS
- type of model atmosphere = spherical
USE CASE 3 :
Show me a list of synthetic spectra satisfying :
- code for spectral synthesis = turbospectrm
- version of this code = 2008.1
USE CASE 4 :
For a given star identified by POS and SIZE, show me a list of spectra satisfying :
- Stokes parameter = Q
- Result of the LSD (code 1) treatment = definite - Linking Lightcurve Points and Source Images In a plot of a lightcurve, people should be able to view the image the flux was extracted from by clicking on a photometric point. Looking at what I think would be under the hood of such a thing, I think there's at least two levels of refinement we could aim for here. Level 1: simply say "this point was derived from this image". A group at the Czech Academy of Sciences already does something like that, and it's fairly harmless: Just add a column with the URL of the image in question. The role the provenance DM has to play there: add some annotation to the field so clients can figure out that a URL that's in there points to the image the photometric point is derived from (more complex provenance scenarios are conceivable). In Level 2, the table would not contain a ready-made URL, but rather some sort of data id and a global reference for a datalink-type service descriptor; the advantage would be that the client can choose how big the cutout retrieved would be. The Provenance DM would in this case have to have some model of accessing artifacts from the provenance chain through datalink/SODA services (which might be something useful beyond just this use case).
- HIPS creation HIPS image should contain information about its progenitors (original fits files)
- Other Projects From the pipeline description of various projects (RAVE, XMM,...) we check how to apply the W3C Provenance Model the main classes
- Off-line Processing An observer want to process again an observation event list to produce level 3 products fitting its science requirements better than those delivered by the routine pipeline. The Provenance model can be use to annotate the regular datasets with the parameters of all tasks operated by the pipeline. This would facilitate the set-up of an off-line processing by refining some of these initial parameter values.
Data Model concepts
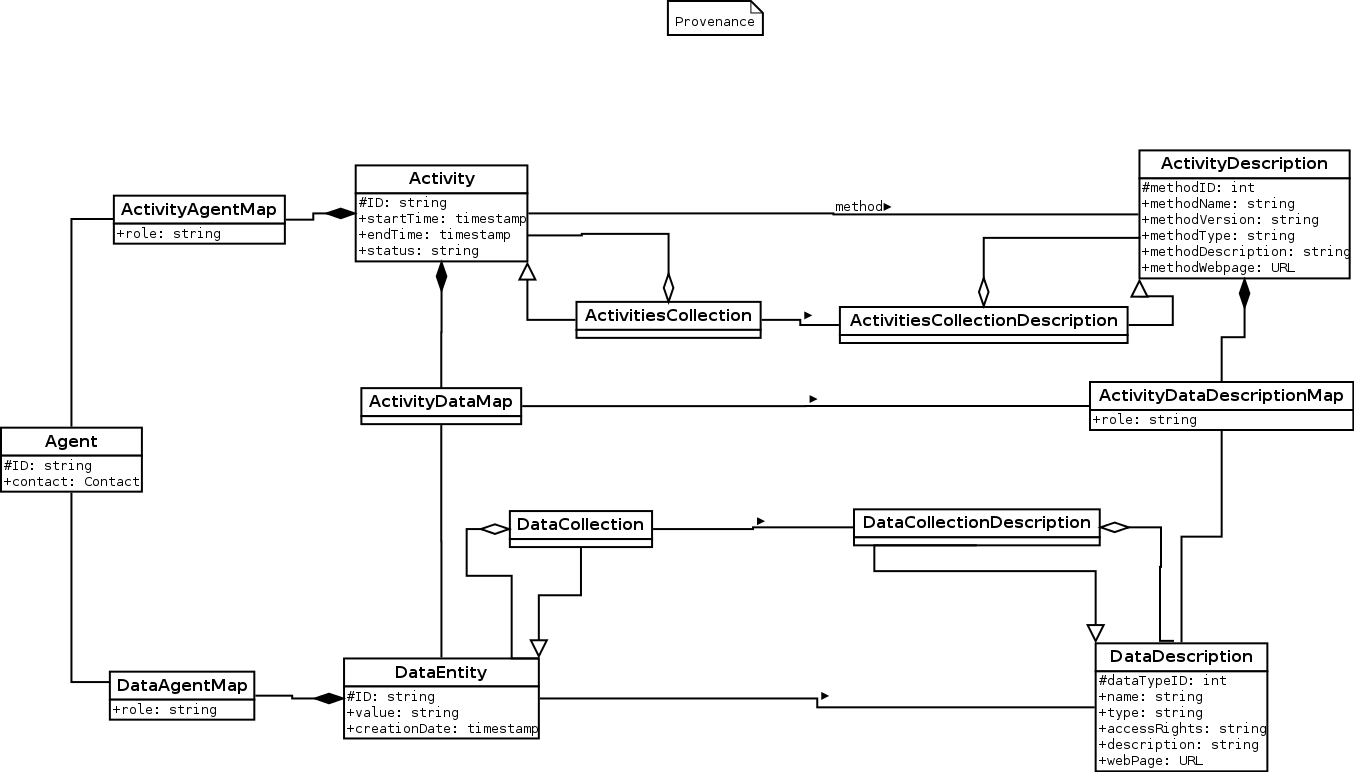
The W3C provenance DM ( http://www.w3.org/TR/prov-overview/ ) offers a pattern Activity/Entity/Agent that seems attractive for current use-cases . We are currently prototyping some use-cases following these ideas.
Provenance DM Vocabulary
Terms describing the provenance relationships from one document or data set already exist in various Data publication projects. ( Datacite, provdm, etc..) We are currently examining the vocabulary needs in the scope of this IVOA Provenance DM. The W3C pattern has 5 main relation ships with qualified roles between the 3 parts Entity/Activity/Agent.- was attributed to Entity --> Agent: may act as contributor, author/creator, publisher etc.
- was derived from Entity --> Entity: points at 'progenitors' data sets role = {isDerivedFrom, IsSourceOf} w.r.t Datacite terms
- was generated by Entity--> Activity: points from an entity to the action, operation the result of which this Entity is.
- used Activity --> Entity
- was associated with Activity --> Agent
Prototyping along the W3C Provenance pattern
-
RAVE prototype XML serialisation
- Spring Interop meeting in Sesto, 2015 by Kristin Riebe: http://wiki.ivoa.net/internal/IVOA/InterOpJune2015DM/Provenance.pdf
-
CTA examples
-
Cf attached files (Example4*)
-
-
Pollux example
-
Cf attached file
-
ProvTAP material
Interactions with other efforts
- DatasetMetadata Data Model
- ObsCore Data Model
- Simulation Data Model
- IVOA Data Access Layer
Requirements from other IVOA WG groups


| I | Attachment | History | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|---|
| |
2019-05-10_IVOA_Provenance_Data_Model.pdf | r1 | manage | 1567.4 K | 2019-05-13 - 08:54 | MathieuServillat | |
| |
ADASSXXVII_Sanguillon_P9-129.pdf | r1 | manage | 107.5 K | 2018-06-01 - 16:51 | MathieuServillat | |
| |
ADASSXXVII_Sanguillon_P9-129_poster.pdf | r1 | manage | 3990.9 K | 2018-06-04 - 08:49 | MathieuServillat | |
| |
ADASSXXVII_Servillat_P4-75.pdf | r1 | manage | 723.9 K | 2018-06-01 - 16:39 | MathieuServillat | |
| |
ADASSXXVII_Servillat_P4-75_poster.pdf | r1 | manage | 2043.9 K | 2018-06-04 - 08:49 | MathieuServillat | |
| |
ADASSXXVI_Riebe_O10-4_v3.pdf | r1 | manage | 128.6 K | 2018-06-01 - 16:35 | MathieuServillat | |
| |
ADASSXXVI_Servillat_P5-5.pdf | r1 | manage | 267.7 K | 2018-06-01 - 16:36 | MathieuServillat | |
| |
ADASSXXVI_Servillat_P5-5_poster.pdf | r1 | manage | 2535.0 K | 2018-06-04 - 08:54 | MathieuServillat | |
| |
ADASSXXV_Sanguillon_P095.pdf | r1 | manage | 512.0 K | 2018-06-01 - 16:43 | MathieuServillat | |
| |
ADASSXXV_Sanguillon_P095_poster.pdf | r1 | manage | 4117.5 K | 2018-06-04 - 09:18 | MathieuServillat | |
| |
CDS-ProvInput-VOT21032018.xml | r1 | manage | 93.2 K | 2018-09-03 - 13:24 | FrancoisBonnarel | Full example in VOTAble by CDS |
| |
Example4.pdf | r1 | manage | 32.8 K | 2015-09-30 - 16:32 | MicheleSanguillon | |
| |
Example4.png | r1 | manage | 934.7 K | 2015-09-30 - 16:32 | MicheleSanguillon | |
| |
Example4.provn | r1 | manage | 15.8 K | 2015-09-30 - 16:32 | MicheleSanguillon | |
| |
Example4.svg | r1 | manage | 190.8 K | 2015-09-30 - 16:33 | MicheleSanguillon | |
| |
IVOA_Provenance_Data_Model_Description.webarchive | r1 | manage | 36.4 K | 2019-04-29 - 19:08 | MireilleLouys | provenance datamodel documentation Modelio description |
| |
PR-ProvenanceDM-1.0-20181015.pdf | r1 | manage | 1015.0 K | 2018-10-23 - 11:44 | MathieuServillat | |
| |
PR-ProvenanceDM-1.0-20190719.pdf | r1 | manage | 1736.8 K | 2020-10-08 - 14:42 | MathieuServillat | |
| |
PROV-N-Example3.txt | r1 | manage | 16.2 K | 2015-09-23 - 13:43 | MicheleSanguillon | |
| |
Pollux-PROV-N-Example1.txt | r1 | manage | 19.9 K | 2015-09-22 - 13:57 | MicheleSanguillon | |
| |
ProvHiPS.xml | r3 r2 r1 | manage | 34.1 K | 2019-10-08 - 04:53 | FrancoisBonnarel | ProvHiPS VOTable as ProvTAP implementation example |
| |
ProvTAP-schema-new.xml | r3 r2 r1 | manage | 31.8 K | 2019-04-15 - 15:33 | FrancoisBonnarel | |
| |
ProvTAP-schema.xml | r1 | manage | 33.7 K | 2019-10-08 - 04:51 | FrancoisBonnarel | ProvTAP TAP schema |
| |
ProvTAP-schema.xml.save | r1 | manage | 20.3 K | 2018-09-03 - 13:12 | FrancoisBonnarel | xml provenance TAP schema |
| |
ProvTAP.pdf | r7 r6 r5 r4 r3 | manage | 611.3 K | 2019-10-08 - 04:50 | FrancoisBonnarel | Provenance metadata TAP protocol |
| |
Prov_Discussion_Notes_201905.pdf | r1 | manage | 46.7 K | 2019-05-31 - 13:02 | MarkCresitelloDittmar | Discussion notes and change list from IVOA interop splinter meetings; May 2019 |
| |
Prov_Document_ChangeList_201905.pdf | r1 | manage | 29.3 K | 2019-05-31 - 13:02 | MarkCresitelloDittmar | Discussion notes and change list from IVOA interop splinter meetings; May 2019 |
| |
Provenance_150930.png | r1 | manage | 60.9 K | 2015-09-30 - 16:34 | MicheleSanguillon | |
| |
Provenance_WD2.pdf | r1 | manage | 1160.9 K | 2019-06-14 - 14:40 | LaurentMichel | |
| |
WD-ProvenanceDM-1.0-20170921.pdf | r1 | manage | 2079.9 K | 2017-09-21 - 21:22 | KristinRiebe | new Working Draft, September 2017 |
| |
WD-ProvenanceDM-1.0-20180530.pdf | r1 | manage | 1266.6 K | 2018-06-01 - 17:28 | MathieuServillat | |
| |
WD-ProvenanceDM-v1.0-20170514.pdf | r1 | manage | 1394.2 K | 2017-05-14 - 14:25 | MireilleLouys | IVOA provenance DM - WD may2017 |
| |
mw-example.html | r1 | manage | 1719.4 K | 2019-05-15 - 13:48 | OleStreicher | Provenance HTML client example |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Topic revision: r91 - 2022-07-20 - MathieuServillat
Log in or Register
IVOA.net
Wiki Home
WebChanges
WebTopicList
WebStatistics Twiki Meta & Help
IVOA
Know
Main
Sandbox
TWiki
TWiki intro
TWiki tutorial
User registration
Notify me Working Groups Interest Groups Committees
www.ivoa.net
Documents
Events
Members
XML Schema
Wiki Home
WebChanges
WebTopicList
WebStatistics Twiki Meta & Help
IVOA
Know
Main
Sandbox
TWiki
TWiki intro
TWiki tutorial
User registration
Notify me Working Groups Interest Groups Committees
www.ivoa.net
Documents
Events
Members
XML Schema
 |
|
Ideas, requests, problems regarding TWiki? Send feedback