This page contains my comments on the
TAP 0.31 spec
First summary of main points, then list of more detailed comments with location intext.
Some of these comments have (no doubt) been noted by others. I have been writing comments down while reading the spec over a couple of days, so may be somewhat repetitive.
Some comments may have been made irrelevant by the recent version 0.4.
NOTE: Notes like this one included below once action has been taken with respect to each point (PD aka PatrickDowler). If TAP doc version is not specified, it is TAP-0.41.
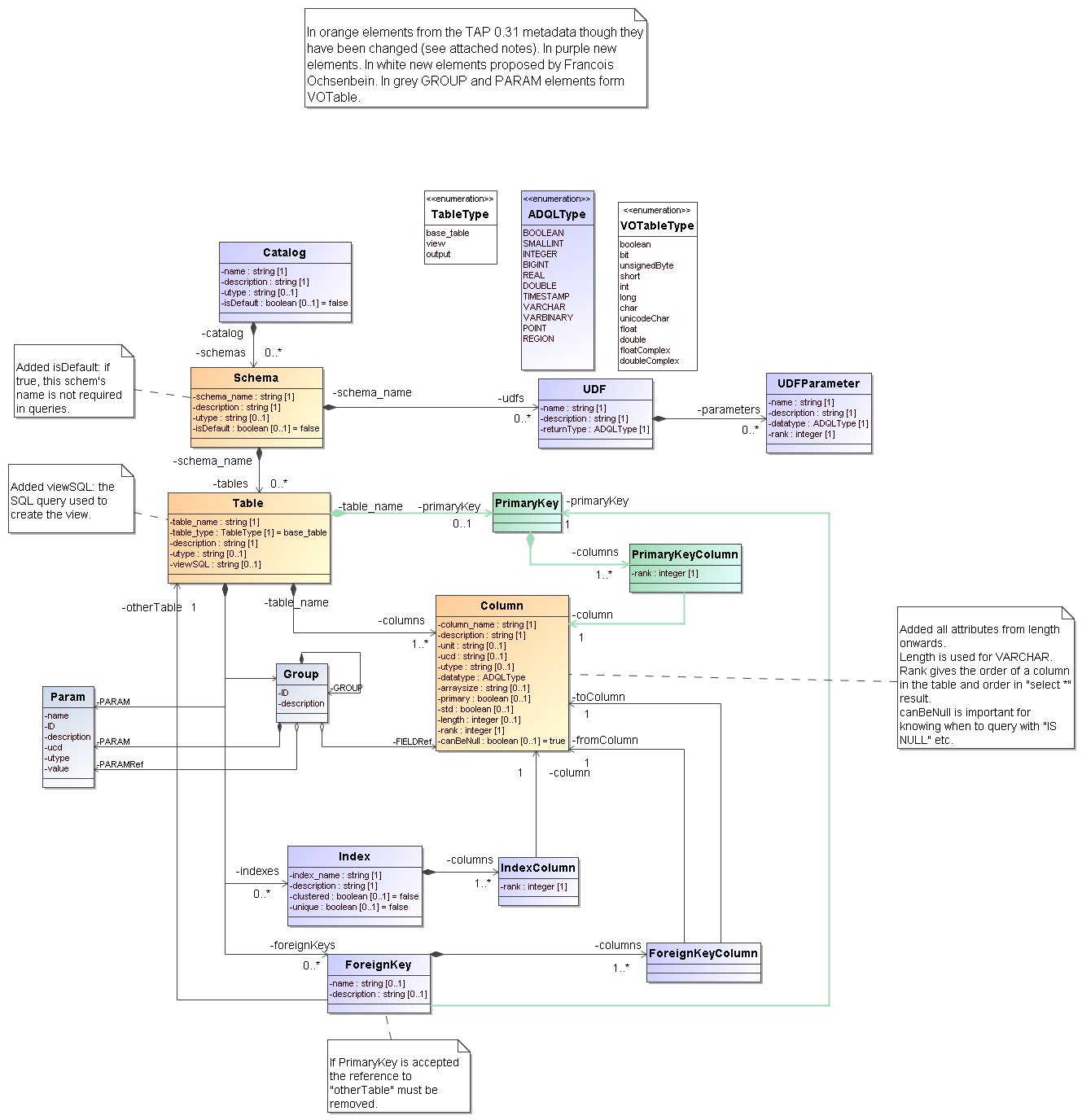
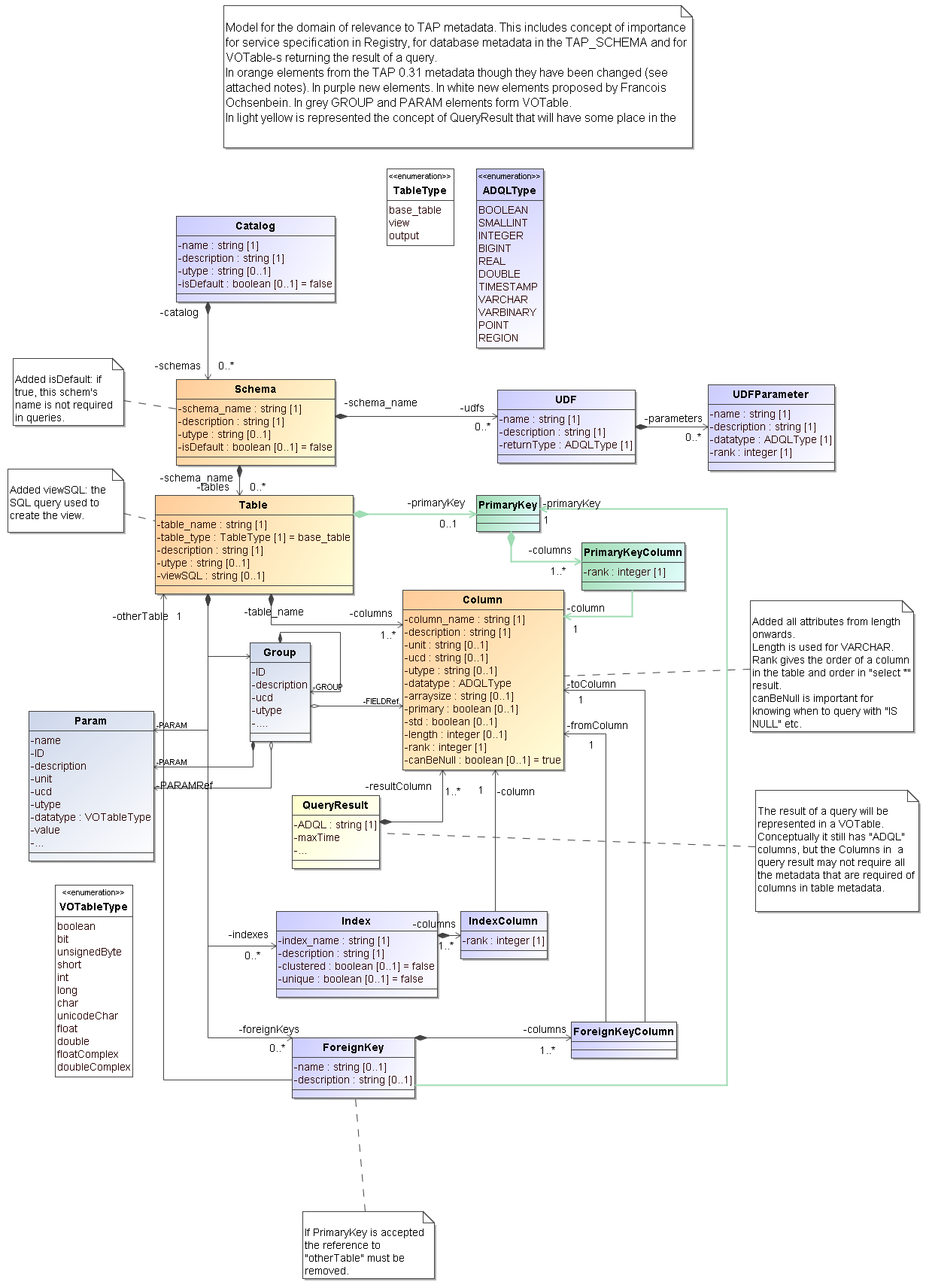 For those who don't like UML, here an attempt at a summary:
For those who don't like UML, here an attempt at a summary:
Major points/issues/questions
- /sync vs /async: I think it preferable if it were possible to make a choice for implementing /sync and/or /async and not mandate both /sync and /asyn ADQL.I think /async is so much harder to implement that a /sync-only service should be allowed, but I can imagine if some implementers would prefer always /async for data queries. I propose that either (or both) is allowed, and should be part of service metadata.
- Metadata: (at the bottom of this page a proposal for a UML data model containing all contents already in TAP_SCHEMA model and extra. From it XML schema and TAP_SCHEMA tables can be easily derived. Based partially on discussions on mailing list.)
- foreign keys MUST be queriable (though may not exists ofcourse), therefore added to metadata
- indexes SHOULD [GL changed from MUST]be queriable (though may not exists ofcourse) , but MUST NOT be specified simply with an index=true attribute on column metadata
- "SQL type" SHOULD (MUST?) be added as possible data type to column metadata. [GL see datatypes page
- IF UDFs are really part of ADQL, metadata about them MUST be queriable (though ... ); maybe here also the standard functions such as INTERSECTS etc should then be specified IF they are supported.
- Grouping of and dependencies between HTTP parameters for the different request types should be made explicit.
- Imho, MAXREC and MTIME parameters should not be mixed with ADQL.
- Case sensitivity: The QUERY parameter is supposed to be case sensitive. Imho this should not be the case.
- ADQL is case insensitive. So are some major online databases (SDSS, Millennium, others?). So are many default settings on relational databases.
- Propose that case sensitivity is only an issue for column values, not (never ?) for names of tables and columns etc.
- Propose to make this a capability, possibly can be added at level of complete database, or schema, or table, or even column level. It is only relevant for (VAR)CHAR columns, maybe the T and Z in iso8601 dates(?).
line-by-line notes/questions/issues
(s=section,p=page,par=paragraph on page or in section).- s1 p4 par2: "... it is not a table containing links to data object ...". I suppose that if someone publishes a table that contains links to data sets, images or spectra, there is no problem with that. Queries might than indeed produce such links.
- s1 end p4: ".. is not visible to users." I don't know whether it is necessarily a good idea to completely abstract away from a user whether there is a relational database on the backend or not. In some sense the fact that one can send ADQL, which is clearly an SQL dialect, makes users expect relational database technology. They may then also expect, and use, some specific database features such as indexes and foreign keys when writing their queries.
- s1 p5 par2: "... joins ... and provided the service supports these capabilities.". I would think that services MUST support joins, as those are an intricate part of ADQL and because service MUST support ADQL queries. Or is it possible to specify that one supports only a subset of ADQL?
- s1 p5 par3:".. conforming to the second generation (DAL2) interface standards [ref]." It would be really good to have this [ref]! Maybe such a "meta-specification" would be a good place to put some of the parameter query specification in.
- s1.1.1: Confusing section. There seem to be at least three ways of querying for table metadata:
- querying standardised tables using ADQL or PARAMQUERY
- tableset queries
- VOSI queries
- s1.1.2 p6 end par2:" ... (ADQL), a standardized subset of SQL92...". Is not quite correct. Is based on SQL92, but no strict subset as it adds extensions such as user defined functions and of course all the REGION stuff.
- s1.1.2 p6 par3: "... use an off-the-shelf ADQL parser...". This is the problem with ADQL, that in general one can not simply pass it through to the underlying database, even if it is properly supplied with the required user-defined-functions.
- s1.1.2 p6 par3: "... simplified parametric queries for the most common use cases." How do we know what the "most common use cases" are? I think this depends strongly on the database. It likely refers to the usual suspect cone search as the most common use case, but is that true? Could be changed to "some common use cases".
- s1.1.3 p6 par3: Use of UWS, which is not accepted yet, in this specification, would seem to require that TAP must define its view of what UWS is. This would be particularly useful for those people who want to implement TAP before UWS is completely accepted. Same is true for possible dependencies on other not-yet-accepted standards such as VOSI.
- s1.1.3 p7 par1: "... there are many more advanced use cases where synchronous queries are not sufficient." I would argue that this has not much to do with how "advanced" a use case is, as with queries requiring lots of work and/or resources on the server side. The query can be as simple as
select * from thattable
, not advanced at all. But it may lead to timeouts/overflows for /sync queries. Whereas other queries make very advanced use of ADQL, and precisely because of that (calculating statistics on the server iso download, proper index usage, proper database design etc) can be supported with /sync just as well. And /sync is MUCH easier to implement.
- s2 "Requirements for a TAP service (normative)" (my italics). It seems to me that there are some requirements in this section that are aimed at clients, not the service. Should identify those and if correct must something be done about that?
- s2.1: As /sync is SO MUCH easier to implement, and can nevertheless provide more than adequate support (from experience with sync-only Millennium database), is it possible to change the requirements to something like: "A TAP service MUST support at least one of sync-ADQL and async-ADQL". I first thought that sync alone should be made mandatory, but I guess some people would like to only implement async.
- s2.1 p9 3rd item in list I would think that table metadata MUST be provided. Without it no queries are possible.
- s2.1 p9 final par "...inheritance of requirements ...". This is relevant as well for SimDB. There we define a global data model for describing (3+1D/space-time/"cosmological") simulations. The model gets a mapping to TAP with the goal that users can use ADQL (sync only necessary!) to query SimDB implementations.
- s2.2 p9 par1+2 and p10 par2 "...service must be represented as a tree structure..." and "... represent the service as a whole" and "...web resource must represent the results...". Is "represent" a formal concept in REST or so. Otherwise what is meant by this? Must everything under the root be related to the service?
- s2.2 p10 par4 "...may return a cached copy...". Don't really understand this paragraph. Isn't this up to service. If it knows that a certain query always corresponds to a particular cached data product, why would it depend on a GET or a POST? Also (see par7) does it mean that /async requests can never return cached data?
- s2.2 p10 par1 and par5 "A TAP service must provide a web resource with relative URL /sync" and "A TAP service must provide a web resource with relative URL /async." See the comment (@*2.1*) above for motivation. Could this be SHOULD or MAY? Or allow implementers to choose one (or both)?
- s2.4 p11 par2 Not all combinations of the parameters are meaningful." Would be good to make an explicit indication of which combinations are valid.
- s2.4.1 p11 par1 "A TAP client must set this parameter correctly ...". This is an example of comment @*2* above, a MUST requirement on a client. Is this appropriate.
- s2.4.1 p11 par2 "If a service receives a spurious parameter ...". Is a parameter that is not in the list of parameters to be considered spurious as well, or is it an error?
- s2.4.1 p11 par1 "If a TAP service receives a request without...". I assume that this concerns a TAP service request that has a /sync or /async added to the root, otherwise it seems to be inconsistent with the last par on p9, which does not mandate error.
- s2.4.1 p11 par2, list Case of allowed values seems to have arbitrary case. Is this to be coordinated with the table on p11?
- s2.4.1 p11 par2, list The statement on getCapabilities, getAvailability and especially getTableMetadata relate to corresponding VOSI metadata.
- As VOSI is not yet an accepted standard (correct?), might be good (formally necessary) to give TAP's view on what this means explicitly. (Or is this done later?)
- Why does this spec, which seems to be the correct specificaiton for defining how to talk to and about table sets/database, defer to another, not yet accepted spec, for table metadata? Actually, there seems to be no tables metadata in VOSI spec at all (I refer to http://www.ivoa.net/Documents/WD/GWS/VOSI-20081023.pdf, is that the correct VOSI spec?)
- s2.4.2 p12 par1 "The query string is case sensitive."
- ADQL spec states (p4, 3rd line; p6 1st line): "Case insensitiveness otherwise stated" and "Both the identifiers and the keywords are case insensitive". So why does TAP go against this?
- IF this is sometimes desirable, could this be a capability and would it be possible to state for a TAP service that it is in fact case0-insensitive. SkyServer and Millennium database are not case sensitive, as MS SQLServer is case insensitive by default. Note that for these databases the case-insensitivity even applies to values of CHAR and VARCHAR columns! The latter is not so in Postgres, though as far as keywords and table and column names also Postgres seems to be case insensitive (at least in my default installation on my desk top pc). Maybe useful to look at report on different database systems by JVO in Victoria. Therefore there might be two modes of case insensitivity: keywords+schema and CHAR values. SQLServer allows case sensitivity, and this can be configured at the column level even. This might imply another metadata element for columns: isCaseSensitive. In any case it would be useful to see how other database handle case sensitivity (by default).
- s2.4.2 p12 par1 "...the case of table and column names must be preserved..." This seems a requirement on the client, or does it imply that if the client uses a different case for a table for example the service MUST report an error?
- s2.4.2 p12 par2 "...the service must support the use of datetime/timestamp values in ISO8601 format." Apparently ISO8601 is still rather liberal and has different versions.
- Is ISO8601:2004 intended?
- Must all of ISO8601(:2004) be supported?
- MS SQLServer 2005 seems not to support all allowed ISO8601 versions, even though it claims it is compatible. For example it seems (in my installation) not to allow yyyymmdd, needs extended version yyyy-mm-dd.
- An overview of other RDBS would be useful.
- s2.4.2 p12 par3 "...enable the caller to perform spatial queries...MUST support the INTERSECTS..." Does this imply that if a published table contains pos.eq.ra and pos.eq.dec columns, one MUST implement INTERSECTS etc. Or are "spatial queries" a separate class of queries (namely those including INTERSECTS and other REGION-like extensions) which one may or may not support. After all
select * from sources where dec between -10 and 10
looks like a spatial query, but does not require INTERSECTS etc.
- s2.4.2 p12 par3 "the extent of STC/S support within the REGION function is left up to the implementation" I can read this as allowing no support for STC string at all, which implies really that I do not support REGION, which I MUST do when supporting spatial queries. Seems not consistent.
- s2.4.2 p12 par4 "...should return an error if ... mix constants and column references for coordinate system and coordinate values." I do not understand the reason for this restriction at all. Also noted by Markus Demleitner I think. This seems like a change to the language, which might even require different parsers/interpreters than one would normally implement. How far does this restriction go. Is the following query ok for example:
select POINT(c.coordSys, t.ra, t.dec) from (select 'ICRS' as coordSys) c , table t ...NOTE: I agree that ADQL allows these and in ADQL discussions where people didn't like the look of such constructs it was argued that this was just the nature of ADQL (SQL) and it's treatment of argument types (literal is equivalent to column ref); this text was included in a provocative manner when it should be simply a warning to users that if they do this they are possibly going to make mistakes. Of course, there are plenty of ways to make mistakes with ADQL and this particular complexity is not going to solve that. Changed text to make this a note/warning in TAP-0.4 (PD).
- s2.4.4 p13 "The service SHOULD implement the LANG parameter." What if the service does not, which language/version is supposed to be supported. Is this a capability ?
- s2.4.5 p13 par1 Could the acceptable MIME types be listed explicitly in the document?
- s2.4.5 p13 list Might it be useful to have an html-table (i.e. starting with <table..> and ending with ) as possible return type. Such a result could be added to a wrapping web page, possibly AJAX like. Might TeX tables be of interest?
- s2.4.5 p13 list Is it allowed for the VOTable to contain data in all its DATA types available, TABLEDATA, BINARY, FITS, also LINKs iso DATA? (Maybe answered in 2.12?)
- s2.4.6 p14 par1 "...name for the table name SHOULD be an unqualified tablename...". Seems a requirement on clients, but not a MUST. What if not obeyed?
- s2.4.7 MAXREC seems not necessary for ADQL, as TOP plays that role there. Useful for ParamQueries though.
- s2.4.7 p14 par4 "...if overflow occurs, MAXREC plus one rows should be returned to indicate that overflow occurred ...". In my opinion, if a user requests that MAXREC rows are to be returned, either using this parameter, or using TOP in ADQL, I think MAXREC rows (or less) MUST be returned, not MAXREC+1. In particular, enforcing this would mean that the obvious implementation (using TOP or LIMIT in the SQL) would need to use TOP ..+1 etc. ONLY if the service's "maximum permitted value for MAXREC" is reached should an overflow warning be give, but in the manner described in 2.8.4, using an INFO element.
- s2.4.7 p14 par5 "..null query, that is, a query which produces an empty table.." In its current form (i,e, using MAXREC) I would not call this a null query, but a null request.
- s2.4.8 I don't think MTIME should be used together with ADQL. IF a table contains a "lastModfied" column, users can use it in their ADQL queries. If there is no such column it is an indication that it is not possible to pose this type of query. It might be suggested that in general it is good practice to have such columns, "createDate", "updateDate",
- s2.4.11 This seems to me a perfect example of a meta-standard suitable for the "DAL-2 family of specifications": how to specify lists and ranges in DAL service parameters. Something similar was specified in SSA already as well. [I guess it has indeed be removed from version 0.4]
- s2.4.13 "Parameter names must not be case sensitive, but parameter values must be so." Seems to conflict with the requirement on LANG in 2.4.4. See also my comment on case sensitivity of ADQL queries above.
- s2.4.14 p17 par2 "Clients should not repeat parameters in a request". Seems to be a SHOULD requirement on clients.
- s2.5 This section seems to belong to 2.6, can it not be merged with that section?
- s2.5 p17 par1 "[[catalog_name.[schema_name.]table_name]]" Following ADQL, shouldn't this be [[catalog_name.]schema_name.]table_name ? Note, if I am not mistaken, ADQL does not allow catalog_name..table_name , i.e. schema_name="" (possible IF catalog_name = ""), something which is allowed in SQLServer and corresponds to using the default schema.
- s2.6 I understand this section to imply that TAP should expose these three tables and make them accessible through ADQL and Param queries. If so, that might be made more explicitly clear. Some comments on the actual metadata prescription (a summary of the proposal can be inferred form the UML diagram at the bottom of this page):
- first table In first row (schema_name), "catalog.schema", should this be [catalog.]schema ?
-
- second table In first row (schema_name), "catalog.schema", should this be [catalog.]schema ?
-
- second table In second row (table_name), "catalog.schema.table", should this be [[catalog_name.[schema_name.]table_name?
-
- second table IN third row (table_type). As apparently views are described in TAP_SCHEMA.tables, I think it would be useful to store the SQL(ADQL?) that defines this view in this table as well. I suggest an extra row, "view_sql, containing the SQL that defines this view (for rows with table_type=view).
-
- third table 2nd row (table_name), "catalog.schema.table" should this be [[catalog.]schema.]table ?
-
- third table, datatype I believe it would be very useful to also have an indication of the SQL type of a column. It is that type, and not its mapping to VOTable types that is of relevance when constructing queries.
-
- third table "indexed" This column is useless. To make proper use of indexes one needs to have their complete definition.This includes all the columns in a given index and the order in which they appear in the index. This may require 2 extra tables. (see the again the data model proposal below).
- third table What are the datatypes of Primary, Indexed and Std? All boolean? How should that be stored in a database? I.e what are valid values for
select primary,.indexed,std from tap_schema.columns
? (I guess 2.11 might say something about this) - s2.6 Metadata prescription for foreign keys is missing but very important. See discussions in same mail thread starting here. A proposal for a model is given in the diagram below again. A proposal for an XML representation is given in http://www.ivoa.net/forum/registry/0811/2023.htm. Note that there has been a discussion between Francois Ochsenbein and me on some details of this model. In particularFO argues that to define a foreign key (FK) one also needs a primary key (PK). Imho this is not required for us here, though indeed it is required in all relational databases. But there FKsrepresent a constraint, whereas in my original proposal they define a pointer only.
- s2.6 Since user defined functions are part of the ADQL language, the metadata should reflect this.I.e. we need a way to query for them. The data model below has a suggestion for modelling this.
- s2.6 p19 par2 "The schema name TAP_UPLOAD should be included in the table name for any tables uploaded to the service by a client." I suppose this is a requirement on the client? Must TAP_UPLOAD also be added in the TAP_SCHEMA.schemas table? * s2.6 p19 par3 "...may be queried for tables named TAP_SCHEMA.*..." Is this intended to imply the following ADQL query?
select * from TAP_SCHEMA.tables where table_name like 'TAP_SCHEMA.%'
-
- s2.6 p19 par4 "...Primary indicates that the column should be visible in the default (narrow) view of a table" I suppose this is only relevant for Param queries?
- s2.6 p19 par4 "Std ... a given column is defined by some standard". What is the relation of this to UTYPE? Is it required. Is it useful without any more indication of what stadard
- s2.6 p19 par5 "A simple tablesetquery must return the entire tableset ..." Very unclear. Why not define it accurately here, or leave the whole description to section 2.8.2?E.g. how does one issue such a query? Certainly (I hope) not by
select * from TAP_SCHEMA.tableset
as that table does not exist. - s2.7 p19 par2 "Tables in the TAP_UPLOAD schema persist only for the lifetime of the query" I suppose the uploaded tables are visible only to the "session" as well.I.e. different requests can upload tables with the same name. How does this work in /async sessions. As long as the query has not completed, should the user be able to find the uploaded tables in other requests. Guess this depends much on UWS functionality?
- s2.7 p20 par7 "... any type of file ... do something useful with the file." I could not find if the document defines such behaviour explicitly. Eg REGION (for STC mask upload?). Otherwise better to remove mention of this (and the STC in example).
- s2.8.1 p20 par3 "... MIME type of text/xml;content=xvotable" Is different from the "application/x-votable+xml" Content-Type in the example in the previous section. Is that how it should be?
- s2.8.1 p21 par1 "If a column value contains a comma the entire column value should be enclosed in double quotes." How do we deal with strings that contain commas as well as double quotes?Suggest to use "standard" that embedded double quotes should be doubled.
- s2.8.1 p21 par 1 "The first data row should give the column name..."
- First, is there a distinction between data rows and other rows?
- Second, can we make this a MUST. What if all returned columns are strings and we can not be sure if first row contains column name.
- s2.8.2 p21 par1 "If the target of the query is the special table TAP_SCHEMA.tableset ...". What is the "target" of a query? Is the value of the REQUEST parameter meant?
- s2.8.2 p21 par2 footnote " a tableset query can be restricted by the WHERE clause of that query" I assume this WHERE clause refers to the ParamQuery WHERE clause?That clause can only contain constraints on a single table, can not include joins. The tableset table does not exists. A tableset represents the whole database, a single WHERE clause can not query that. I would say this option of restricting a tableset XML document should not be available, as it needs to be defined properly and likely leads to unnessecary complications.Through ADQL users can query all the metadata tables in any way they want. Through the getTableMetadata/XML they get all metadata in one go. Why add more ill defined complications?
- s2.8.2 p21 par3 "The special use of VOTable must be a dataless VOTable in which the header elements denote the structure of the tableset"An alternative use of VOTable for representing table sets would be for it contain the serialisation of the TAP_SCHEMA tables as individual table elements.In the current proposal new features have to be introduced into the VOTable spec for each new metadata feature we may think of: indexes, foreign keys, primary keys. The fact that Francois has added some way to deal with the latter two to the new VOTable proposal is likely mainly to cover this case?
- s2.8.2 p21 par3 "...there MUST be on VOTable element per table ..." I assume this should read: "...one TABLE element per table..."?
- s2.8.3 p21 par1 "Representations of VOSI outputs ... table metadata) must be as defined in the VOSI standard [6]" I do not see any mention of table metadata in the VOSI spec. In any case I do not see why TAP, which is the main spec for defining database metadata,should defer to another spec for representing that. I'd think it is TAP's responsibility to define the complete content of the metadata, others should follow it. That includes the VODataServices spec. This comment is a duplicate of one above, but still relevant.
- s2.8.5 "Overflows" (already commented on above) I think the only overflow that can happen and should lead to an error info message is when the service returns fewer rows than the client might have recieved if there are no restrictions set by the service. If the client explicitly asks for a maximum of 1000 rows, through TOP (or MAXREC for param queries)to be returned, and there are 1000 rows available, 1000 should be returned, WITHOUT ANY MESSAGE OR EXTRA ROW! If the user asks explicitly, or implicitly (no TOP/MAXREC) for more than the service is willing to return, then I think the service should return the its maximum number of rows but give a warning message indicating this truncation.I would not even in that case add an extra row. The info message should be explicit and sufficient. I believe VOTable 1.2 has explicitly for this purpose a closing INFO element in its DATA?
- s2.10 I suppose that all parameters defined in this section are deemed irrelevant when query=ADQL. I would include therefore the subsection on MTIME and MAXREC in this section, as well as section 2.4.11. [I guess that version 0.4 takes care of part of this.]
- s2.10 I think that parts of this section could be usefully extracted and made into separate spec. In particular the "meta-specification" on how to create ranges, lists as values forparameters have already been needed and used in SSA for example. A proper BNF for these would be good, as is used here for the WHERE clause only.This could be the "Common elements in the DAL2 family of services" specification.
- s2.10.3 p27 par1 "The must implement a SELECT parameter" I suppose this should be "The service MUST support a SELECT parameter." ?As ParamQuery is otional, a TAP service must accept SELECT parameters without error, but need not implement it.
- s2.20.5 p28 par4 "the field observer must contain the case insensitive substring smith" First I guess that the boldfaced-ness of the must here is inappropriate. Does not correspond to meaning in IETF RFC 2119 I think. Case-insensitiveness is inconsistent with statements elsewhere in the spec.
- s2.10.5 p29 par1 "... not attempted to detail the BNF for the numeric, string, and date tokens". Considering that later in the section special forms of the string parameter are described, it would be good if the BMF would be complete.
- s2.11 p30-31 par1 How should one query a database that declares to have a boolean column? Should DB understand both 0/1 and false/true?This may be a charge to ADQL parsers/transformers. Could it be a capability for a boolean column? Note that boolean does not exist in SQL92, and in sql99 has values true and false (and null).
- s2.12 p33 par2 "then the output may also use multiple columns". I would think it depends only on the query what is returned. If a user queries
select ra, dec ...
than the service MUST return an ra and a dec column. - s2.12 p33 par3 "and may be aggregated with the VOTable GROUP construct" I would think this is quite difficult to do correctly, and easy to do wrong especially for ADQL queries.It requires a parser to understand a query in great detail, more then we might expect from the of-the-shelf parsers taht will be written. And is it necessary. When a user submits a query,(s)he is assumed to understand the schema and the query and understand how things belong together.
- (maybe more later)
- TAP_METADATA.jpg:
For those who don't like UML, here an attempt at a summary:
- database [name,description, utype]
- schema [name,description, utype]
- table/view: [name,description, utype, sql (for views)]
- column [[name,description, utype,datatype, ucd, etc]
- foreignkey [toTableName, ...]
- foreignKeyColumn [fromColumnName, toColumnName]
- index[name, description, ...]
- indexColumn [columnName, rank]
- group [name, id, ...]
- columnRef [columnName, rank]
- param(Ref) [...]
- group(Ref) [...]
- param [name, ucd, ..., value]
- table/view: [name,description, utype, sql (for views)]
- schema [name,description, utype]
- QueryResult
- Result column
- ?source column?


| I | Attachment | History | Action | Size | Date | Who | Comment |
|---|---|---|---|---|---|---|---|
| |
TAP_METADATA.png | r3 r2 r1 | manage | 115.5 K | 2009-04-17 - 13:25 | GerardLemson | Added query result |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Topic revision: r31 - 2009-04-17 - GerardLemson
Log in or Register
IVOA.net
Wiki Home
WebChanges
WebTopicList
WebStatistics Twiki Meta & Help
IVOA
Know
Main
Sandbox
TWiki
TWiki intro
TWiki tutorial
User registration
Notify me Working Groups Interest Groups Committees
www.ivoa.net
Documents
Events
Members
XML Schema
Wiki Home
WebChanges
WebTopicList
WebStatistics Twiki Meta & Help
IVOA
Know
Main
Sandbox
TWiki
TWiki intro
TWiki tutorial
User registration
Notify me Working Groups Interest Groups Committees
www.ivoa.net
Documents
Events
Members
XML Schema
 |
|
Ideas, requests, problems regarding TWiki? Send feedback